An anagram is a word (or phrase) that you get by rearranging the letters of another word (or phrase), for example:
LISTEN
SILENT
ELEVEN PLUS TWO
TWELVE PLUS ONE
Traditionally, an anagrammist (i.e., someone looking to create anagrams) might start with a name and then look for interesting/humorous/clever anagrams, but there are plenty of other ways to hunt for anagrams. One notable alternative comes from NPR’s “Weekend Edition” (May 5, 2002), where the challenge was to: find two countries whose letters can be rearranged to form two other countries; for example: MALI + QATAR = IRAQ + MALTA. In this case, we aren’t starting with a specific word/phrase we want to anagram, but rather we’re given a list of countries and are happy if we find any pairs of countries that are anagrams of each other.
Given a list of countries (and the help of a computer), it’s not hard to find the other three examples:
ALGERIA + SUDAN
ISRAEL + UGANDA
BELARUS + INDIA
LIBERIA + SUDAN
GABON + ITALY
LIBYA + TONGA
In fact, Noam Elkies proposed a fancier algorithm (implemented here) that makes quick work of finding larger sets of countries that are anagrams of each other, e.g.:
BULGARIA + GABON + INDIA + LIECHTENSTEIN + ROMANIA
BENIN + CAMBODIA + ISRAEL + LITHUANIA + NIGER + TONGA
And, of course, that algorithm works with any word list, not just countries, so if you feed it a list of chemical elements, you can find (among many other examples):
ARGON + HELIUM + NEON + NIOBIUM + SULFUR + TERBIUM + TIN
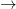
BISMUTH + FLUORINE + NITROGEN + NOBELIUM + URANIUM
That algorithm relies on a nice computational “sledgehammer”: lattice reduction (which is not the focus of this post, although it may show up in future posts).
As clever as that algorithm is, though, it has limitations. For example, it’s not obvious how to extend the same ideas to find more than two sets of words that are all anagrams of each other, such as these three sets of countries:
ALGERIA + BAHRAIN + CHINA + CONGO + CUBA + INDIA + ISRAEL + ITALY + SAMOA + VANUATU
CANADA + CHILE + CROATIA + GABON + GAMBIA + LITHUANIA + NAURU + SLOVENIA + SYRIA
CHAD + GUYANA + HAITI + LATVIA + LEBANON + LIBERIA + MONACO + NICARAGUA + RUSSIA
Finding these types of anagrams requires some different ideas, which are sketched-out in the rest of this post, culminating in the following ten sets of countries that are all anagrams of each other:
ALBANIA + BRAZIL + CAMEROON + GREECE + INDIA + MALDIVES + SOUTH SUDAN + SPAIN + TAIWAN + TONGA + TURKEY
ALGERIA + BENIN + BOLIVIA + CHAD + COMOROS + GUYANA + PANAMA + SWITZERLAND + UKRAINE + UNITED STATES
ANDORRA + AUSTRIA + KENYA + LIECHTENSTEIN + MOLDOVA + SAINT LUCIA + SINGAPORE + UGANDA + ZIMBABWE
ARGENTINA + BARBADOS + CHILE + DOMINICA + EAST TIMOR + NEW ZEALAND + PAKISTAN + SLOVENIA + URUGUAY
BANGLADESH + BRUNEI + CROATIA + EGYPT + IRELAND + MAURITIUS + MONACO + SLOVAKIA + SWEDEN + TANZANIA
BELIZE + DENMARK + INDONESIA + LAOS + NAURU + NEPAL + RUSSIA + RWANDA + THE GAMBIA + TOGO + VATICAN CITY
BOSNIA AND HERZEGOVINA + CYPRUS + ERITREA + ESTONIA + GABON + ICELAND + KUWAIT + MALI + MALTA + SUDAN
BOTSWANA + COSTA RICA + NIGER + OMAN + PALAU + SERBIA + SYRIA + THAILAND + UNITED KINGDOM + VENEZUELA
COLOMBIA + ECUADOR + GRENADA + LITHUANIA + NORWAY + PERU + SAINT KITTS AND NEVIS + SENEGAL + ZAMBIA
ESWATINI + GERMANY + GUINEA + LATVIA + MOROCCO + NETHERLANDS + POLAND + SAUDI ARABIA + UZBEKISTAN
Plan of Attack
To find our anagrams, we’re going to proceed in three steps:
- Find a distribution of letter (e.g., 10 As, 2 Bs, 6 Cs, etc.) that is likely to have many anagrams.
- Find all the sets of countries that have letter-counts that match the distribution from Step 1.
- Find the largest collection of non-overlapping sets from Step 2.
And along the way we’ll make use of some computational “sledgehammers” to make our life easier.
Step 1:
Let’s start by studying the distribution of letters in a list of 196 countries:
A 274
B 50
C 51
D 57
E 128
F 11
G 46
H 34
I 161
J 7
K 21
L 69
M 55
N 146
O 96
P 26
Q 4
R 102
S 83
T 87
U 73
V 18
W 12
X 2
Y 20
Z 15A reasonable place to start would be to assume that our anagrams will have a similar distribution of letters, since they will be built up from the same set of words. For instance, if we assume that our anagrams will each contain roughly 6 countries, then we can multiply the above letter counts by 6/196 (and round to the nearest integer) to conclude that we should look for subsets of countries that have 8 As (since 274 x 6 / 196 = 8.388…), 2 Bs (since 50 x 6 / 196 = 1.531…), no Fs (since 11 x 6 / 196 = 0.337…), etc. Below, we’ll see that we can be a bit smarter in this step, but for now let’s just go with a multiplier of 6 / 196.
Step 2
Now that we have a target set of letter frequencies, we need to find sets of countries that have exactly those letter frequencies. To do this, we’ll use our first computational sledgehammer: a “SAT solver“. “SAT” is a shorthand for the “Boolean Satisfiability Problem“, which is essentially the problem of finding solutions to formulas where the variables are binary (i.e., the only valid values are TRUE=1 and FALSE=0). SAT is a foundational topic in computer science and has been studied extensively. While there are a variety of reasons to believe that SAT is a hard problem to solve, there are also impressive “SAT solvers” that do quite well on practical instances, which is what interests us here. To read (much) more about this fascinating topic, check out Chapter 7 of Donald Knuth’s The Art of Computer Programming.
In order to use a SAT solver, we need to transform our anagram problem into a Boolean formula. Here’s a natural way of doing just that. Define Boolean variables:
$$x_1, \ldots, x_{196}$$
where 
AFGHANISTAN, ALBANIA, ALGERIA, . . ., ZIMBABWE
Then if we want exactly 8 As, we can form a clause that looks like:
$$ (x_1 + x_1 + x_1) + (x_2 + x_2 + x_2) + (x_3 + x_3) + \cdots + x_{196} = 8$$
[
Strictly speaking, this sum is not a Boolean clause (because it involves addition), but there are a variety of ways to efficiently transform these kinds of “cardinality constraints” into proper Boolean clauses (see, e.g., Knuth).
Now, our Boolean formula will simply be a conjunction of these constraints for each of the 26 letters:
$$\varphi = \mathcal{C}_A \wedge \cdots \wedge \mathcal{C}_Z.$$
By feeding this formula to our SAT solver, it quickly finds a solution where:
$$ x_{19} = x_{50} = x_{82} = x_{104} = x_{112} = x_{124} = x_{130} = x_{152} = 1$$
and all other
BHUTAN + ECUADOR + ITALY + MALDIVES + MONACO + NIGER + PAKISTAN + SERBIA
because BHUTAN is the 19th country in the list and ECUADOR is the 50th, etc., and by hand it’s easy to check that this solution does have 8 As, 2 Bs, etc.
Now we want to find additional solutions, so we’ll add a clause to the Boolean formula that excludes the solution we already found:
$$\varphi_1 = \mathcal{C}_A \wedge \cdots \wedge \mathcal{C}_Z \wedge (\neg x_{19} \vee \neg x_{50} \vee \cdots \vee \neg x_{152}).$$
By passing this formula to our SAT solver, we find another solution:
BENIN + BHUTAN + COTE D’IVOIRE + LAOS + MADAGASCAR + MALI + SPAIN + TURKEY
Continuing in this way (adding a new constraint after each new solution is found), we find a total of 10 sets of countries that match the target letter counts (and hence are all anagrams of each other):
BHUTAN + ECUADOR + ITALY + MALDIVES + MONACO + NIGER + PAKISTAN + SERBIA
BENIN + BHUTAN + COTE D’IVOIRE + LAOS + MADAGASCAR + MALI + SPAIN + TURKEY
ARGENTINA + CAMBODIA + CUBA + IRAN + LESOTHO + MALDIVES + SPAIN + TURKEY
BRUNEI + CHAD + DENMARK + EGYPT + LAOS + LATVIA + MONACO + SERBIA + TUNISIA
CYPRUS + GABON + ICELAND + INDIA + MALTA + SERBIA + SOUTH KOREA + VIETNAM
BRUNEI + CAMBODIA + CHAD + ISRAEL + LAOS + SPAIN + TONGA + TURKEY + VIETNAM
BHUTAN + DOMINICA + ECUADOR + EGYPT + LAOS + SERBIA + SRI LANKA + VIETNAM
BARBADOS + CHILE + ECUADOR + EGYPT + OMAN + SRI LANKA + TUNISIA + VIETNAM
BHUTAN + CABO VERDE + ICELAND + MALI + PAKISTAN + SURINAME + SYRIA + TOGO
BELARUS + BENIN + CHAD + ECUADOR + MALI + PAKISTAN + SYRIA + TOGO + VIETNAM
But we’re not quite done yet, because these sets are overlapping: BHUTAN is reused in several of these sets, as are SPAIN, TURKEY, VIETNAM, etc., which feels a bit like “cheating” or, at the very least, isn’t as elegant as a solution where no sets overlap.
Step 3
Finally, we need to sift through our 10 anagrams from Step 2 to find as many as possible that are non-overlapping. This is exactly the Set Packing problem, which also came up when tackling this tiling problem, and we can solve it using another computational sledgehammer: Integer Programming. Specifically, we’ll create a 0-1 matrix that encodes the sets we found in Step 2:
$$\begin{matrix}\mathrm{ARGENTINA} & \mathrm{BARBADOS} & \mathrm{BELARUS} & \mathrm{BENIN} & \mathrm{BHUTAN} \cdots \\ \hline 0 & 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 1 & 1 \\ 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 1 \\ 0 & 1 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 1 \\ 0 & 0 & 1 & 1 & 0 \end{matrix}$$
and the goal is to find the largest possible collection of non-overlapping rows. Passing this matrix to an integer programming solver, it instantly finds that the 3rd, 4th and 9th solutions are non-overlapping:
ARGENTINA + CAMBODIA + CUBA + IRAN + LESOTHO + MALDIVES + SPAIN + TURKEY
BRUNEI + CHAD + DENMARK + EGYPT + LAOS + LATVIA + MONACO + SERBIA + TUNISIA
BHUTAN + CABO VERDE + ICELAND + MALI + PAKISTAN + SURINAME + SYRIA + TOGO
and it also shows that there’s no solution that involves more than three non-overlapping rows.
Refinements
Now that we have a recipe for finding multiple subsets of countries that are anagrams of each other, how large a set of anagrams can we create? One limitation above was that our search in Step 2 only turned up 10 different sets of countries that matched our target letter counts; however, if we tweak the distribution from Step 1 a bit we can increase the number of solutions. For instance, instead of taking 6/196 times the letter frequencies, we could look at 7/196 or 8/196, etc. and the number of solutions in Step 2 increases rapidly (which also leads to larger solutions in Step 3):
| Multiplier in Step 1 | # of solutions in Step 2 | Size of solution in Step 3 |
| 6/196 7/196 8/196 9/196 10/196 | 10 175 1242 4865 87,152 | 3 6 6 6 7 |
But there’s a trade-off: as we increase the multiplier from Step 1, the solutions in Step 2 contain more and more countries, so it’s going to be harder and harder to find many non-overlapping sets in Step 3.
There are also some constraints imposed by the relatively rare letters that we’ll want to take into account. For example, J, Q & X each appear fewer than 10 times and F only appears 11 times in the whole list. So, if we want to create 10 (non-overlapping) sets of countries we’ll have to ignore countries that have a J, Q or X in them (so long, FIJI, QATAR, MEXICO, etc.). And now that we’ve eliminated FIJI, we’ll also have to ignore countries that have an F because one of the countries on the list is “FEDERATED STATES OF MICRONESIA”, which has 2 of the 10 remaining Fs. Proceeding in this way, we can prune the list of countries to eliminate these kinds of problematic cases, leaving a list of 170 countries that don’t use any of the letters F, J, Q or X.
Using this revised list of countries, we can start over at Step 1, now with a slightly different letter distribution. With a little bit of trial-and-error, it turns out that a good multiplier to use in Step 1 is 9/170, which leads to 4397 sets in Step 2, and then in Step 3 there is a set packing with 10 sets:
ALBANIA + BRAZIL + CAMEROON + GREECE + INDIA + MALDIVES + SOUTH SUDAN + SPAIN + TAIWAN + TONGA + TURKEY
ALGERIA + BENIN + BOLIVIA + CHAD + COMOROS + GUYANA + PANAMA + SWITZERLAND + UKRAINE + UNITED STATES
ANDORRA + AUSTRIA + KENYA + LIECHTENSTEIN + MOLDOVA + SAINT LUCIA + SINGAPORE + UGANDA + ZIMBABWE
ARGENTINA + BARBADOS + CHILE + DOMINICA + EAST TIMOR + NEW ZEALAND + PAKISTAN + SLOVENIA + URUGUAY
BANGLADESH + BRUNEI + CROATIA + EGYPT + IRELAND + MAURITIUS + MONACO + SLOVAKIA + SWEDEN + TANZANIA
BELIZE + DENMARK + INDONESIA + LAOS + NAURU + NEPAL + RUSSIA + RWANDA + THE GAMBIA + TOGO + VATICAN CITY
BOSNIA AND HERZEGOVINA + CYPRUS + ERITREA + ESTONIA + GABON + ICELAND + KUWAIT + MALI + MALTA + SUDAN
BOTSWANA + COSTA RICA + NIGER + OMAN + PALAU + SERBIA + SYRIA + THAILAND + UNITED KINGDOM + VENEZUELA
COLOMBIA + ECUADOR + GRENADA + LITHUANIA + NORWAY + PERU + SAINT KITTS AND NEVIS + SENEGAL + ZAMBIA
ESWATINI + GERMANY + GUINEA + LATVIA + MOROCCO + NETHERLANDS + POLAND + SAUDI ARABIA + UZBEKISTAN
Conclusion
Usually an algorithm is considered “good” if it has some clever tricks that allow it to avoid trying to solve notoriously difficult problems (like SAT, set packing and other NP-complete problems), but the approach here is different: The “sledgehammer approach” relies on understanding (intuiting?) what types of practical problems are well-suited to computational sledgehammers like lattice reduction, Boolean satisfiability or Integer Programming. This approach doesn’t guarantee that we’ll always find a solution in a reasonable amount of time, but when it does work it can lead to results that might have been very hard to come by using more traditional algorithms.
Leave a Reply